在日常生活在,你的网页、小程序、APP,是否有过以下情况?
当类似上述故障发生时,最痛苦的莫过于“救火队”——运维人员,不仅需要耗费大量时间进行排查,而且不能很好定位到是前端的问题还是后端的问题,前后端IT人员的互相甩锅,也导致问题迟迟无法解决。
我们以一些典型的场景为切入,来看看排障定位为什么会出现如此困境:
01. 运维痛点——排障过程存在困境
1)单点用户排障流程
过去传统运维单点排障的工作实录:用户纷至沓来,客服电话被打爆,运维人员看看堆积如山的工单汗如雨下。只能一个个工单进行故障排查。
运维人员打开第一条工单,发现是个普通的JS错误报错,但是只能看到异常错误堆栈信息,无法通过这个堆栈直接定位到错误的源代码行。只能抱着这个异常错误去自行解析。好不容易解析出了源代码异常的位置,并测试了几轮,完成了源代码修复。
运维人员打开第二条工单,解析完发现这是跟第一个一模一样的错误源代码行,也就是说,在完成第一个异常修复的时候,其实就已经同时完成了这条异常的修复。运维人员骂骂咧咧地打开第三条工单、第四条工单,一条一条解决着........
终于,在运维人员加班到十二点,解决完第433条工单,看着待办1000+后。啪地一声关上了电脑。
结果自己该做的其他工作,一点进度都没有。
2)前端排障原理与流程
当然,随着代码技术的不断演进,现在的程序员一般是不会一行一行的去排查代码的,不然动辄上万行的代码,如此去排障,运维人员、前后端人员早就“崩溃”了。以JS异常为例,我们来看两个实例:
① 简单情况下的问题定位
大部分程序编写过程中,程序引擎会有定位异常行号的功能,但当部分引擎不具备定位行号功能时,几乎无法定位异常所在。在这种情况下,程序员们会使用TRY…CATCH语句,标记要尝试的语句块,并制定一个出现异常时的响应机制。
举例:
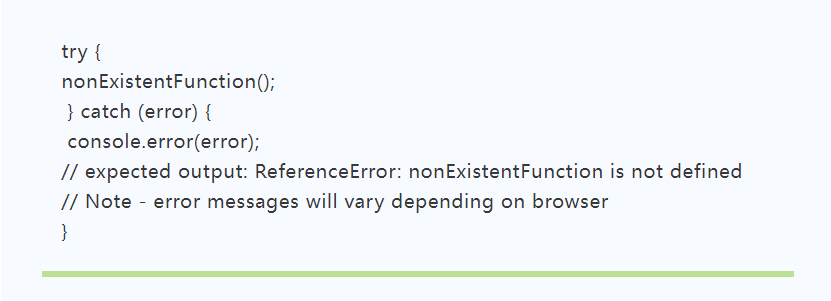
捕捉到异常之后,可以通过Error的lineNumber属性将行号打印出来:

借此,完成异常代码的定位。
② 复杂情况下的问题定位
当然,上例是比较简单的代码的情况,可以通过TRY…CATCH语句进行一条条的定位。
实际生产环境中,一般的网页代码都是体量较大的, 并且前端的JavaScript代码在上线前都会经过压缩、混淆处理,这样的好处是可以减小代码的体积,二来可以保证代码的安全性。例如某网页源代码可能是这样的:

在经过压缩、混淆后变成了这样:

在这种情况下,如果发生代码报错:

那么就很难根据错误信息去定位具体的代码行。
该例子中还有 auto_renew 这个关键字,能根据关键字入手,实际情况可能更加复杂,如仅提示“Cannot read property [0] of undefined”时,定位具体问题将变得更加棘手。
③ SourceMap精准定位问题
如何解决复杂情况下的代码异常定位问题呢?
如果不压缩代码,直接用源码去进行发布工作,看似可以完美的解决异常,但是代码体积将会非常巨大,同时安全隐患也无法忽视。那为什么在本地开发的时候,默认的也是打包后的文件,用chrome测试的时候为什么就可以看到源码呢?这就不得不提SourceMap技术了。
所谓SourceMap技术,就是维护一个源代码和压缩后代码映射关系用的文件,通过压缩后的错误信息反向推出源代码的具体错误行号。
例如上述代码,map文件内容如下:

其中,最重要的内容就是mappings这一行。这是一个很长的字符串,分为了三层,记录了一搜索前后代码的映射关系。现在常用的的前端打包工具(webpack、gulp、rollup等)都支持这个SourceMap功能。
打包后类似:
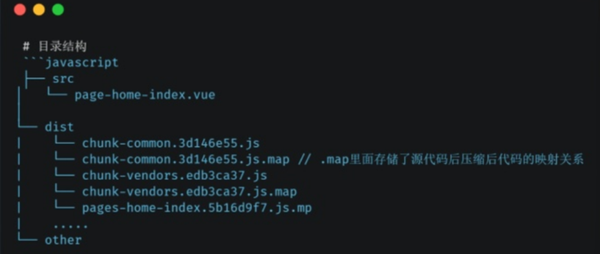
另外需要注意,SourceMap是不会跟着打包后的js一起部署的,不然你的代码很容易就被他人反推出来。所以需要在打包脚本过程中,将其中的.js和.map独立出来。
借助SourceMap技术,通过合适的展示平台,如嘉为鲸眼真实用户监测中心,就可以在展示平台中精确定位到异常错误行。
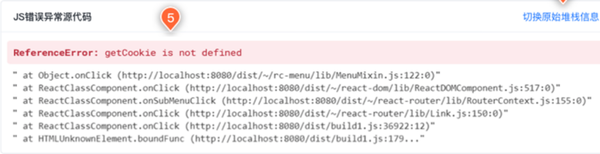
除JS异常外,前端还会有许多其它类型的异常,还存在种各种各样的排障困境,但实际上,只要弄清楚造成困境的根本原因,从本质出发着手处理,问题就迎刃而解了。
02. 根因分析——前后端分离的监控差异
1)前后端监控的差异
在当下流行前后端分离开发的大趋势下,APM技术(应用性能监测,也就是后端服务监测)也更多的被大家所认知。
当前,随着用户端的复杂度的上升以及精细化运营的需求上升,对流量层的监控已发展至第三阶段,从专注于网络、IT部件/组件的后端监控转向前端后端一体化监控,从用户端着手开始采集数据,同时在整个用户体验交付链条的每一个环节都要进行监控,完成基于云的端到端全栈应用性能管理。
从用户端的角度看,用户操作一条信息大致是通过如下流程的:
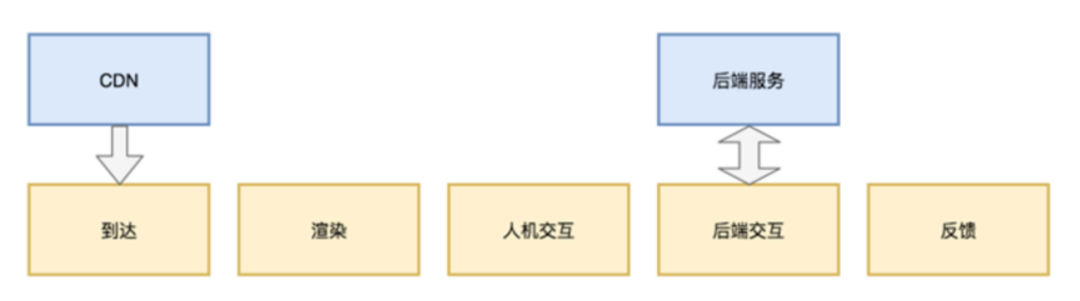
这其中的每一个环节都可能产生缺陷:
到达环节
- CDN资源加载错误
- 资源响应超时导致用户跳出
渲染环节
- 排版错乱
- 白屏或者模块缺失
- 元素隐藏或遮盖
交互环节
- 无法选中某些元素
- 无法取消/删除/退出
请求环节
- 请求参数错误
- 网络连接失败
- 返回格式不正确
- 性能太差导致用户放弃
反馈环节
- 结果无法确认,造成页面假死或者重复提交
- 提供错误提示。
而在传统的监控体系下,这一系列环节中只有后端交互的部分能够用常规的后端监控工具,即APM覆盖到,其它环节的监控往往是缺失的。
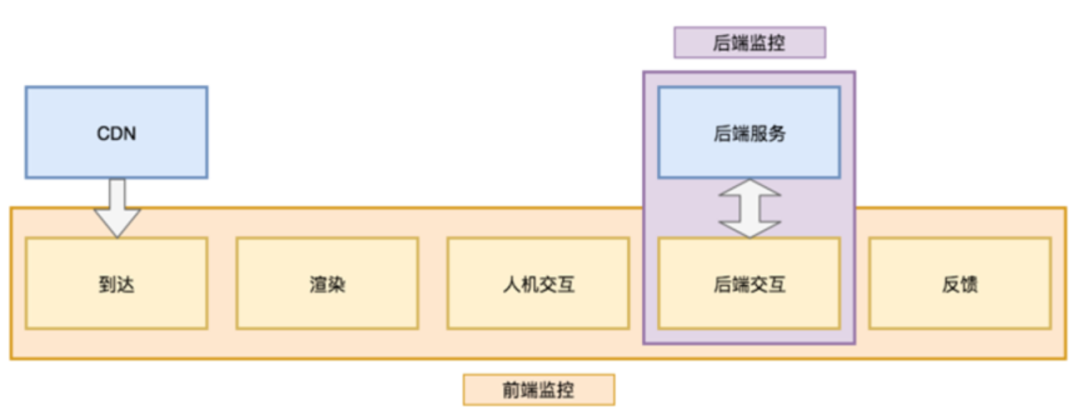
因为缺乏这方面监视的工具,前后端同事也经常进行问题的“甩锅”。

为防止前后端的“撕逼”,我们需要从什么角度去建立前端监控体系,保证前后端的工作定位准确,精准排障呢?
03. 对症下药——跨越障碍实现精准排障
从用户端来看,任何一个角度出现问题,都会导致用户的体验不佳,导致流失。为了保证用户不流失,一些APM解决方案开始引入UEM(user experience monitoring)技术,即针对用户体验的监控,来保证可用性。
由于用户端的复杂度不断上升,我们面临的偶发性缺陷,局部性缺陷等难以复现的问题会越来越多。
用户端作为一个高度碎片化的系统,在任何个例上可用都不意味着整体可用,可用性问题实际上是按各种环境因素展开的概率问题。
影响可用性的环境因素:
- 地区 - CDN或者接口服务的可用性有地域差异
- 时间 - 部分业务逻辑受时间影响,包括本地时间、服务器时间、时区等因素
- 渠道 - 除了产品的主App之外,还可能有公众号、浏览器应用、交叉推荐、运营推广等各种合作渠道
- 版本 - 新老版本永远共存,可能产生兼容性问题
- 账户 - 新用户与老用户,注册账户与第三方账户
- 操作 - 用户的操作方式可能是专业人员意想不到的
从这些角度出发去分析问题,就可以撅弃传统的“反馈、复现、调试”的缺陷处理方法。通过前端主动上报监控信息的形式,收集更全面的用户端数据,用“打点、观察、分析”的方法,以统计学思维处理概率性的缺陷,而不是直接通过前后端一同还原现场深入细节排障的方式,就能够避免甩锅现象的发生。
前后端监控工具的相互联动,能够让运维人员提供加强故障感知能力,保证业务连续稳定,同时也便于研发人员进行异常根因分析,精准定位问题,从而跨越前后端鸿沟,实现全方位排障流程的效率提升。
相关文章推荐
100+案例淬炼:应用投产变更管理最佳实践

 2026-02-09
2026-02-09
查看详细


嘉为蓝鲸DevOps|业务人员跨界修缺陷?AI 打通DevOps全链路,提效超乎想象!
2026-02-09
查看详细
【运维自动化规划】自动化作业设计:从原子操作到流程编排的工程化实践
2026-01-09
查看详细
嘉为蓝鲸DevOps研发测试一体化:从信息孤岛到双向穿透,构建高效协同新范式
2026-01-09
查看详细
嘉为蓝鲸DevOps缺陷管理协同中枢:破解 “单测多研” 质量困局,打造高效协同新范式
2025-12-26
查看详细
【运维自动化规划】自动化场景设计:从组件级到混合场景的全链路自动化构建
2025-12-26
查看详细







